|

(20 novembre 2010) |
|
(20 novembre 2010) |
L’informatique est « la science du traitement rationnel, notamment par
machines automatiques (ordinateurs), de l'information considérée comme
le support des connaissances humaines et des communications dans les
domaines technique, économique et social » (définition approuvée par
l'Académie française).
Un historien est une personne qui étudie ou communique sur l’histoire.
A partir de témoignages, de faits historiques et de restes d’époque, il
a pour tâche de rapporter des faits passés, de les catégoriser, puis
d'en proposer une interprétation équilibrée et justifiée par des
sources. Il travaille souvent à partir d’ouvrages, de journaux, de
documents d’archives.
L’informatique peut donc rendre d’immenses services à l’historien en
améliorant son efficacité dans la recherche de données, dans leur
archivage ou leur interprétation. C’est ce que nous allons essayer de
montrer à partir de quelques exemples concrets et à partir de notre
modeste expérience d’utilisateur de l’informatique, au quotidien, pour
nous informer ou communiquer, ainsi que pour archiver ou exploiter des
données. Et ce, dans des domaines aussi divers et variés que les
recherches sur l’histoire locale ; l’archivage d’articles de presse,
d’ouvrages d’une bibliothèque, de photographies ou de films ; la
gestion de fichiers d’adresses, de fichiers bibliographiques, de
biographies d’hommes célèbres, de glossaires linguistiques, de
collections de plantes, d’insectes ou de minéraux, de cave à vins, etc.
Tout commence par la numérisation des données. C’est donc ce que nous
examinerons en premier lieu. Dans une seconde partie, nous traiterons
de l’exploitation des données numérisées au moyen de quelques logiciels
informatiques : le traitement d’image, le traitement de texte, la
reconnaissance de caractères, le tableur et la base de données. Dans
une troisième partie, nous donnerons une série d’exemples concrets sur
l’apport de l’informatique dans l’étude de notre histoire locale et
notamment dans l’étude des patronymes seynois.
 |
| Jean-Claude Autran |
1) La numérisation des documents
La numérisation permet de convertir un objet du monde réel (texte sur
support papier, image, musique, séquence vidéo, impulsion électrique,
etc.) en un code numérique, c’est-à-dire en une suite de nombres qui
permettent de représenter cet objet en informatique, permettant ainsi
sa « lecture » et son exploitation par un ordinateur.
Cette numérisation peut être réalisée, par exemple, par un scanner, un
appareil photo numérique, ou un caméscope numérique.
L’intérêt de la numérisation est multiple. Lorsqu’on a affaire à des
documents uniques, ou rares, tels que des manuscrits originaux, ou des
ouvrages en cours d’épuisement en librairie, la numérisation permet de
les sauvegarder, de les archiver, de les stocker, de les dupliquer
(disquettes, disques durs, CD-ROM, DVD,…), de les agrandir (fonction
zoom), de les transporter (clés USB), de les transmettre à distance
(messagerie électronique). C’est une première révolution qui, pour ce
qui est du grand public, date du début des années 1990. Quelques années
plus tard, il est devenu possible de partager l’information contenue
dans les fichiers numériques grâce au développement du réseau internet.
A titre d’exemple, les 10 ouvrages écrits par Marius AUTRAN, et qui
étaient alors pratiquement tous épuisés, ont été numérisés au début des
années 2000 et sont devenus consultables sur un ordinateur personnel ou
sur internet. Il en est de même pour l’association Histoire
et Patrimoine Seynois qui met en ligne, au fur et à mesure de leur
parution, les actes de tous ses colloques précédents.
 |
| Ouvrages de Marius Autran |
 |
| Fichiers numériques de la série d'ouvrages de Marius Autran (avec Tome 2 détaillé) |
 |
| Accès aux ouvrages de Marius Autran mis en ligne sur internet |
Les textes numérisés prennent très peu de place dans la mémoire d’un
ordinateur. Un livre de 400 pages (le texte uniquement), occupe environ
1 méga-octet (1 Mo). Un giga-octet (1 Go) permet donc de stocker
l’équivalent de 1 000 ouvrages. Une minuscule clé USB de 8 Go : 8 000
ouvrages ! Et un disque dur, aujourd’hui courant, de 1 téra-octet (1
To) : 1 million d’ouvrages ! L’ensemble des textes [sans les supports
photos ou vidéos] de la Bibliothèque Nationale, une fois numérisés,
tiendraient donc dans une simple mallette.
Pour l’historien qui travaille, par exemple, sur l’état-civil, les
tables décennales, les recensements, les délibérations des
communautés d’habitants, le cadastre, les archives
notariales, etc., la numérisation de tous ces documents désormais
réalisée et mise en ligne sur internet par la majorité des départements
français, constitue donc un avantage considérable puisque la
consultation peut désormais se faire depuis son ordinateur personnel. A
titre d’exemple, travaillant sur notre généalogie personnelle, 10 ans
avaient été nécessaires pour identifier un millier d’individus. Lorsque
l’état-civil du Var fut accessible sur internet (vers janvier 2007),
1000 nouveaux individus ont pu être rajoutés en moins de 3 mois, sans
qu’il soit nécessaire de prendre de rendez-vous et de se déplacer aux Archives Départementales.
 |
| Accès aux Archives Départementales du Var, mises en ligne sur internet |
 |
| Une page du recensement de La Seyne de 1836 (rue Franchipani), en ligne sur internet |
2) Les logiciels d’exploitation des documents numérisés
Nous avons dit que tout document historique pouvait être numérisé
(scanner, appareil photo, caméscope). Il est ainsi devenu aujourd’hui
extrêmement classique de travailler sur des images numériques.
Contrairement aux photographies argentiques (ou aux microfilms encore
utilisés dans de nombreuses bibliothèques), une image numérique peut
être envoyée à distance en pièce attachée, ou partagée sur des sites
internet. Elle peut aussi, grâce à des logiciels de traitement d’images
(exemple : Photoshop), être agrandie ou réduite, ou encore «
retravaillée » (luminosité, contraste, couleurs,…), ou même retouchée
pour en retirer des imperfections.
 |
| Un fragment du cadastre de La Seyne de 1829 (Les Moulières) en ligne sur internet |
Mais, s’agissant de textes d’ouvrages, de rapports dactylographiés ou d’actes manuscrits, une image numérique n’a d’intérêt qu’en matière de sauvegarde, d’archivage, d’économie de papier ou d’encre, d’économie de place dans le stockage de l’information. Une page de livre, ou une page de recensement, une fois numérisée, n’est en effet qu’une image comme une autre et il n’est généralement pas possible d’y appliquer de critère de recherche, ou de tri ou de classement car elle n’est pas structurée en caractères, mots, lignes, paragraphes, tableaux, etc. Il faut donc savoir qu’il y a numérisation et numérisation… Il y a la numérisation qui conduit à une simple image numérique, et il y a celle qui permet de redonner à une page la structure d’un texte.
 |
| Exemple de page (p. 786) de l'Histoire de La Seyne de L. Baudoin (image numérique) |
 |
| La même page (p. 786) de l'Histoire de La Seyne de L. Baudoin (après reconstitution du texte) |
Un texte numérisé ne peut être en effet pleinement exploité que s’il
est structuré par un logiciel de traitement de texte tel que Word,
OpenOffice, etc. Aujourd’hui, la plupart des documents qui sont rédigés
le sont directement au moyen d’un tel traitement de texte. Il en est de
même des textes qui apparaissent sur internet.
Rappelons qu’un texte numérisé possède de nombreux avantages par
rapport à un texte sur papier : facilité de correction et de remise en
forme, « couper-coller », possibilité de retrouver un mot, insertion
d’images ou de graphiques, correction orthographique et grammaticale,…
Et aujourd’hui, avec la puissance des machines, toute opération est
devenue quasiment instantanée, même sur des textes très volumineux.
Prenons l’exemple de l’Histoire de La Seyne de Louis Baudoin et
supposons que nous recherchions un nom qui a été cité à un
certain endroit du texte (mais où ?). Feuilleter, parcourir les 900
pages et les chapitres peut prendre des heures, avec le risque de
renoncer avant d’avoir trouvé. Supposons maintenant que nous disposions
d’un fichier numérique de ce même livre. La recherche d’un mot
particulier utilisé à un endroit quelconque de l’ouvrage devient alors
extrêmement facile grâce à la fonction recherche du traitement de texte
: le logiciel va nous conduire à la page en question en moins d’une
seconde. Il en serait de même s’il s’agissait d’une encyclopédie en 17
volumes. Et que dire des moteurs de recherche utilisés sur internet,
qui arrivent aujourd’hui à analyser plusieurs milliards de pages et
repérer les sites contenant l’information recherchée en moins de 0,2 ou
0,3 seconde !
 |
| Recherche d'un nom (exemple : Burgard) cité dans le livre de M. Baudoin : la fonction recherche du traitement de texte permet d'amener instantanément le lecteur à la page 752 du livre et de surligner (jaune) les occurrences du mot recherché |
 |
| Exemple de détection d'une faute typographique oubliée par l'auteur, grâce au logiciel de traitement de texte (flottille, et non flotille - souligné en rouge) |
Mais, s’agissant d’ouvrages ou autres documents écrits anciens, un
rattrapage considérable s’impose pour les rendre disponibles sous forme
de traitement de texte. Si de nombreux ouvrages classiques ont été
numérisés par des organismes (Google Books) et sont devenus disponibles
sur internet, il n’en est pas de même pour des ouvrages à tirage limité
tels que nos livres d’histoire locale. Mais les retaper manuellement
est extrêmement long et fastidieux.
C’est pourquoi ont été développés des logiciels de reconnaissance
optique des caractères (exemple : OmniPage). Le document papier est
soumis à un scanner, mais cette fois-ci, après numérisation, le
logiciel analyse chaque page et « extrait » de l’image toute forme
ayant une apparence de caractère d’imprimerie et reconstitue ainsi les
mots et les phrases du texte, comme s’il avait été retapé dans un
traitement de texte. Même avec un logiciel d’amateur, quelques dizaines
de minutes suffisent pour numériser un ouvrage.
Naturellement, ce procédé ne fonctionne qu’à partir de pages de livres,
ou de documents correctement imprimés ou dactylographiés. Partant de
textes anciens ou de papiers jaunis, des erreurs de reconnaissance de
caractères se produisent, obligeant à une relecture attentive et à de
nombreuses corrections manuelles. A partir de documents de médiocre
qualité, et à fortiori de manuscrits tels que des actes d’état-civil,
la reconnaissance devient impossible et une saisie manuelle des textes
au clavier est obligatoire.
 |
| Fonctionnement de la reconnaissance optique de caractères à partir d'une page numérisée d'un texte |
 |
| Exemples d'erreurs de reconnaissance de caractères à partir d'un document de mauvaise qualité |
S’agissant de documents historiques présentés sous forme de tableaux,
tels que les recensements de la population, une saisie manuelle des
informations est nécessaire puisque, jusque vers les années 1960, il
s’agit de manuscrits. C’est un travail initial considérable, mais qui
est cependant facilité par les nombreuses possibilités que
l’informatique offre : dupliquer, « couper-coller », « glisser-déposer
»,… qui font qu’on n’a pas à tout retaper.
Une fois l’information saisie, elle va pouvoir être exploitée au moyen
de deux autres familles de logiciels.
Le recensement est le type de document qui se prête à une exploitation
au moyen de logiciels dit tableurs, dont le type est Excel.
Un tableur est une feuille de calcul électronique formée de lignes et
de colonnes qui permet de réaliser des calculs automatiques et des
statistiques, ou de créer des présentations graphiques, chaque case de
la feuille pouvant contenir du texte, un nombre ou une formule
mathématique.
La figure suivante montre comment un registre de recensement peut être
présenté sous forme d’une feuille de tableur, avec les colonnes : rue,
numéro, nom, prénom, année de naissance, lieu de naissance, profession,
etc.
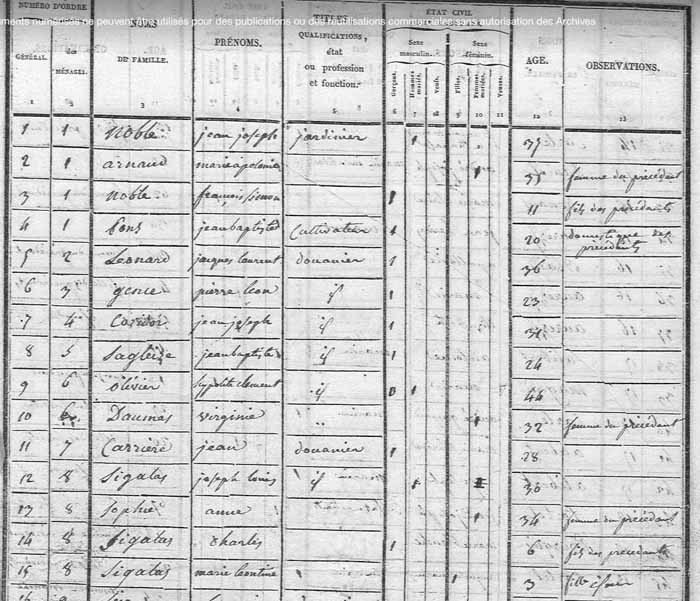 |
| Extrait du recensement de 1836 (image numérique) |
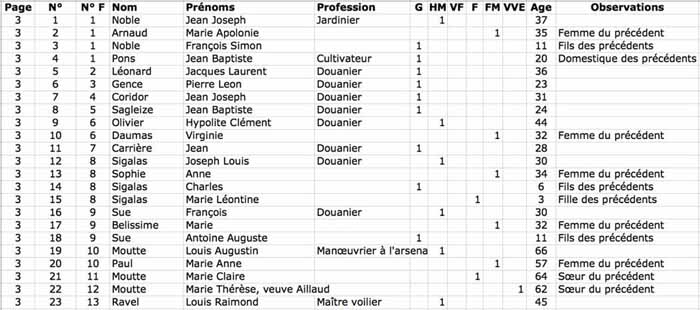 |
| La même page présentée sous Excel (tableur numérique) |
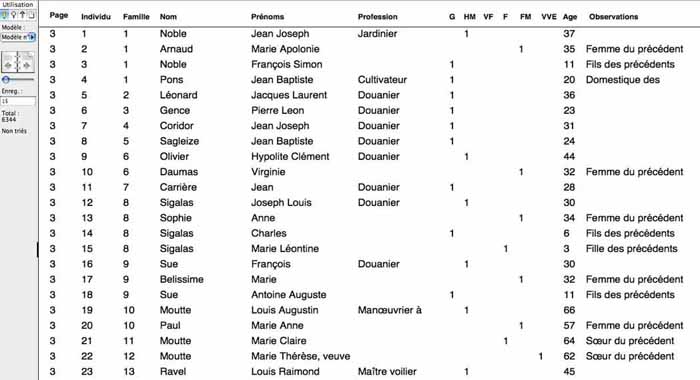 |
| La même page présentée sous FileMaker (base de données) |
Une fois l’information saisie dans un tableur elle va pouvoir être
convertie facilement sous un dernier type de logiciel, la base de
données (DataBase, FileMaker,…)
Une base de données est une version informatique du traditionnel «
classeur de fiches », chaque fiche comportant différentes « rubriques
». Par exemple, dans un fichier d’adresses : le nom, le prénom, le
numéro et la rue, le code postal, la ville, le pays, le téléphone, etc.
Mais les anciennes fiches en papier cartonné étaient difficiles à
manipuler dès qu’on en avait plusieurs milliers, ou même seulement
quelques centaines. La recherche d’une information ou le reclassement
des fiches était très long et fastidieux. Le repérage d’une rubrique
obligeait à avoir des onglets de couleurs différentes, ou des encoches,
ou des cases cochées ou noircies pour être reconnues par un trieur
optique…
L’avantage des bases de données informatiques actuelles est de posséder
non seulement des fonctions de recherche ou de tri automatique quasi
instantané, mais aussi la possibilité d’extraire un sous-ensemble de
fiches correspondant à une rubrique donnée.
La figure suivante montre ainsi la structure d’une fiche informatique extraite
d’un fichier de gestion d’une bibliothèque personnelle d’ouvrages. Il
s’agit de la fiche d’un ouvrage de René Merle, Gentil n’avait qu’un
œil. On y trouve les différentes rubriques : titre, auteur, année,
éditeur, catégorie, n° ISBN,…
 |
| Exemple de fiche informatique (Gentil n'a qu'un œil, de René Merle) extraite d’un fichier de gestion d’une bibliothèque personnelle d’ouvrages |
Un fichier informatique ainsi constitué va pouvoir être « interrogé » pour, par exemple, extraire tous les ouvrages d’un auteur donné. On va pouvoir, tout aussi facilement, retrouver les ouvrages parus en telle année, dans telle rubrique, ou chez tel éditeur. On peut aussi « s’amuser » à faire des recherches multiples telles que : quels sont les ouvrages de type roman historique, parus entre 1950 et 1960, dont l’auteur a pour prénom Pierre, et qui ont moins de 200 pages ?… Le logiciel permet de répondre à n’importe lesquelles de ces questions, quasi instantanément, que le fichier contienne 100, 1 000 ou 20 000 fiches. Rien de tel n’aurait pu être accompli sans l’informatique.
 | |
| Exemple de recherches des titres d'un auteur donné (Jacques Girault) dans un fichier numérique d'ouvrages |
|
3) Apport de l’informatique dans l’étude des patronymes seynois
On rappelle que les archives départementales du Var ont numérisé (sous
la forme d’images) et mis en ligne sur internet tous les recensements
disponibles entre 1836 et 1906, rendant possible leur consultation
depuis son ordinateur personnel.
Pour permettre l’analyse détaillée des recensements de La Seyne et des
patronymes seynois, nous avons retenu certains d’entre eux pour en
saisir le contenu manuellement sous forme de tableurs et de bases de
données. Le travail a pu être réalisé entièrement sur le recensement de
1836 (le plus simple à traiter puisque la ville n’avait alors que 6 344
habitants), et pour l’instant partiellement sur ceux de 1856 (7 928 habitants),
1876 (10 245 habitants) et 1906 (18 685 habitants).
La version « tableur » du recensement de 1836 est un tableau comportant 6344 lignes et 14
colonnes.
La version « base de données » est un fichier comportant également 6 344 enregistrements et 14 rubriques, au sein desquelles toute recherche, simple ou multiple, peut-être désormais effectuée. Ci-dessous, un fragment du tri alphabétique des individus.
 |
| Fragment du recensement de 1836, en version « base de données », après tri alphabétique |
Car, disposant des données des recensements ainsi numérisés, tout
devient « ludique ». On peut « s’amuser » à répondre très facilement à
n’importe quelle question. Par exemple :
Quels sont les patronymes les plus représentés à La Seyne en 1836 ?
DANIEL (119), GIRAUD (100), POURQUIER (74), PASCAL (71), AUDIBERT (68), ESTIENNE (67), ARNAUD (67), MARTINENQ (63), HERMITTE (63), MICHEL (59), GRAS/GROS (57), BERNARD (55), ANDRIEU (53), CURET (51), OLLIVIER (50), DENANS (48), PAUL (47), CADIERE (46), VIDAL (44), PRAT/DEPRAT (44), etc. (Entre parenthèses, le nombre d’individus portant ce patronyme).
Si l’on retrouve bien dans cette liste la plupart des patronymes
six-fournais d’avant la séparation La Seyne-Six-Fours du XVIIe siècle,
leur fréquence a changé. Des patronymes autrefois extrêmement
représentés à Six-Fours, comme : MARTINENQ, AUDIBERT, DENANS, CURET,
FABRE, etc. sont devenus nettement moins fréquents à La Seyne. Le
patronyme AYCARD a même, quant à lui, pratiquement disparu à La Seyne.
A l’inverse, les DANIEL, GIRAUD, POURQUIER, PASCAL, ESTIENNE, ARNAUD,
etc. sont devenus plus courants à La Seyne qu’ils ne l’étaient
auparavant à Six-Fours.
Et en 1906 ?
BLANC (56), GIRAUD (47), MARTIN (34), PASCAL (30), AUDIBERT (28), ROUX (28), ARNAUD (27), PONS (26), BOYER (24), MICHEL (24), JOURDAN (23), DALMASSO (23) *, VIDAL (22), IMBERT (22), FABRE (22), MARRO (22) *, GIRAUDO (20) *, BRUNO (20) *, VIALE/VIAL (20) *, DECUGIS (19), BOTTERO (19) *, etc. (Entre parenthèses, le nombre de familles portant ce patronyme)
On observe qu’apparaissent désormais des patronymes italiens (*), pas
dans les tout premiers rangs mais dans une proportion qui commence à
compter.
Ceci ne constitue pas un « scoop », car n’importe quel comptage manuel
des patronymes aurait permis, avec de la patience, d’aboutir à cette
conclusion. Ce sur quoi nous voulons insister, c’est que le travail sur
les données numérisées des recensements a permis d’y parvenir
automatiquement, et en quelques secondes.
Les prénoms, les métiers, les âges
A partir des fichiers numérisés des recensements, une étude similaire
peut être effectuée sur les prénoms, les métiers, les âges, les % de
célibataires, de marié(e)s, de veufs ou veuves, etc.
Ainsi, à La Seyne, en 1836, la fréquence des prénoms masculins les plus
représentés est la suivante : Jean (455), Joseph (433), Louis (200),
François (182), Pierre (180), Antoine (166), Etienne (95), Laurent
(88). Pour les prénoms féminins : Marie (766), Victoire (171), Thérèse
(162), Magdeleine (156), Claire (152), Elizabeth (139), Rose (136),
Joséphine (126), etc.
Tandis que les prénoms les plus « rares » (1-2 individus) sont, chez
les hommes : Achille, Alcide, Bénoni, Chrisologue, Généreux, Hilarion,
Lanfrède, Marc, Philoxène, Policarpe, Spiridion ; et chez les femmes :
Alfrède, Andréline, Angeline, Eusébie, Eutrope, Hiacinthine,
Innocentine, Nazarine, Pélagie, Radégonde, Théodorine...
Les métiers les plus fréquents à l’époque sont les suivants : marin
(532), cultivateur (453), charpentier (136), pêcheur (66), domestique
(59), boulanger (53), maçon (50), ouvrier à l’Arsenal (48), tuilier
(43), capitaine marin (42), etc.
Et parmi les moins fréquents : berger (11), portefaix (6), tisserand
(5), tonnelier (3), meunier à farine (1), voiturier (1), pourvoyeuse
(1), regrattier (1).
On peut naturellement en éditer les noms, les prénoms, les âges, etc.
Par exemple :
- Combien y avait-il d’instituteurs et d’institutrices à La Seyne en 1836 ? Réponse : 10.
- Qui étaient-ils (noms, prénoms, âge, situation familiale…) :
- 6 instituteurs : LOMBARD Augustin, 73 ans, veuf ; MARTINI Jean-Baptiste, 41 ans, marié ; MARTINI Adrien, 18 ans, célibataire ; MICHEL Joseph, 47 ans, marié ; PONCET de PRADON Louis, 71 ans, marié ; VICARD Alexandre, 24 ans, célibataire.
- 4 institutrices (en majorité des religieuses) : AUDIBERT Victoire, 52 ans, célibataire ; FASSI Marie, 53 ans, veuve ; GEOFROY Elizabeth, 36 ans, célibataire ; GUIRAND Pauline, 34 ans, célibataire.
A partir des mêmes données des recensements, on peut réaliser aussi
facilement une recherche croisée sur plusieurs rubriques. Par exemple,
répondre à des questions du type :
- Qui étaient les boulangers de La Seyne en 1836 ? Ils étaient 54, dont
: boulangers sans spécification (30), maîtres boulangers (2), ouvriers
(14), garçons (6), etc. Leur âge moyen : 37,9 ans. 30,0 % étaient
célibataires, 66,7 % mariés et 0,3 % veufs.
 |
| Quelques-uns des boulangers de La Seyne en 1836 |
Métiers féminins
A l’époque, à l’exception des veuves obligées de prendre un emploi
rémunéré, la très grande majorité des femmes travaillaient au foyer.
L’informatique permet très facilement d’en faire une analyse précise :
- Sexe féminin : 3 214 sur 6 344 habitants, 1 550 filles, 1 247 femmes mariées, 417 veuves.
- Principaux emplois féminins : domestiques (51), journalières (39), blanchisseuses (10), marchandes (7), revendeuses (5), repasseuses (4), tailleuses (3), divers (4).
- Au total : seulement 123 femmes ont un emploi (7,4 %), dont 40 emplois occupés par des veuves (9,5 %).
Recherche sur plusieurs rubriques
En effectuant une recherche multicritères, on peut ainsi « s’amuser » à
répondre à n’importe quelle question du type :
- Combien d’agriculteurs de moins de 30 ans ?
- Combien de marins invalides ?
- Combien d’ouvriers de l’Arsenal de plus de 40 ans et célibataires ?
- etc.
On peut également (lorsque les recensements fournissent cette rubrique,
à partir de 1846 seulement) inclure dans la recherche le nom de la rue
ou du quartier. A titre d’exemple :
- Combien d’habitants à Saint-Elme en 1906 ? Réponse : 108.
- Parmi ceux-ci, combien étaient pêcheurs professionnels ? Réponse : 19
- Leurs patronymes ? ATTANASIO (2), CARDONE (1), CHRISTIN (2), COCADRILLO (1), DOUCE (1), GAUDEMARD (2), GIORDANO (1), LIGUORI (1), MORI (1), PIGNATEL (2), SAUVAIRE (1), SOPARLADO (1), VIOLO (3).
On y retrouve des noms de famille bien connus, dont plusieurs ont
aujourd’hui donné leur nom à des rues du hameau de Saint-Elme.
Comme les recensements indiquent toujours la nationalité des habitants,
on peut également suivre l’évolution du nombre d’immigrés,
majoritairement italiens, au fil des années, et même rue par rue.
A partir des versions numérisées des recensements, on a
étudié, par
exemple, la population du cours Louis-Blanc, et les résultats
ont été
exprimés sous forme de graphiques grâce au tableur Excel.
De 300 habitants en 1846, la population du cours Louis-Blanc a
atteint 450 en 1866, puis s’est stabilisée autour de 350
en 1876 et
1906. Parmi ces habitants, les patronymes italiens, bien qu’en
légère
augmentation, sont toujours restés en faible proportion.
Au contraire, rue Nicolas-Chapuy, la population n’a cessé de croître :
100 habitants en 1846, 170 en 1876 et 370 en 1906. Et avec une
proportion toujours prédominante des patronymes italiens.
 |
| La population du cours Louis Blanc de 1846 à 1906 (graphique Excel) |
 |
| La population de la rue Nicolas Chapuy de 1866 à 1906 (graphique Excel) |
Mais, curieusement, on ne trouve pas les mêmes patronymes parmi les
habitants respectifs de ces deux rues. Sur le cours Louis-Blanc, ce
sont les patronymes : BADINO, BALLAÜCO, BARBERO, CASTELLI, DUTTO,
FERRERO, GIRAUDO, MARRO, PASSALAQUA, VALLETTA, etc. Et dans la rue
Nicolas-Chapuy : CAVALLO, CAVALLERO, DALMASSO, FALCO, GIORDANO,
MENFRETI, MUSSO, ROSSI, SERENO, SIMONDI, TALLONE, TOSELLO, VIALE,
ZUNINO, etc. Aucun patronyme ne se retrouve à la fois cours Louis-Blanc
et rue Nicolas-Chapuy.
Encore une fois, il n’y a rien d’extraordinaire dans ces observations.
Ce qui est intéressant, c’est qu’elles ont été obtenues en quelques
fractions de seconde, par l’interrogation des fichiers numériques. Et
que le même travail peut être mené, à la demande, et aussi facilement,
sur n’importe quelle rue, n’importe quel patronyme, n’importe quel
critère de recherche.
Pour conclure
Après avoir montré par quelques exemples l’intérêt que peut apporter
l’informatique aux historiens, il convient d’apporter quelques « bémols
» :
1) La saisie informatique des données manuscrites anciennes demeure un
travail assez considérable.
2) On a tendance à conserver tout ce qui nous est nécessaire dans la
mémoire de son ordinateur. Un inconvénient pourrait être que l’on perde
peu à peu l’habitude de mémoriser.
3) Pour économiser papier et encre, et préserver l’environnement, on a
plus en plus tendance à « dématérialiser » les rapports ou autres
documents, à les conserver dans nos ordinateurs et à les diffuser par
messagerie. Mais il ne faut pas oublier que ces données informatiques
demeurent fragiles. Un incident sur l’ordinateur, un vol, un incendie
peuvent faire perdre des années de travail. Même les CD-ROM ou les DVD
ne sont pas éternels. Deux règles sont donc à suivre absolument. Règle
n° 1 : faites une sauvegarde de vos données ! Règle n° 2 : faites une
deuxième sauvegarde !… que vous stockerez en un lieu différent de la
première.
Retour à la page d'accueil des archives et souvenirs de Jean-Claude Autran
Retour à la page d'accueil du site
 |
|
 |
© Jean-Claude Autran 2013
